在互联网的业务系统中,涉及到各种各样的ID,如在支付系统中就会有支付ID、退款ID等。那一般生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种适合自己的解决方案是十分重要的。下面我们一一来列举一下,不一定全部适合,这些解决方案仅供你参考,或许对你有用。
一个ID一般来说有下面几种要素:
- 唯一性:确保生成的ID是全网唯一的。
- 有序递增性:确保生成的ID是对于某个用户或者业务是按一定的数字有序递增的。
- 高可用性:确保任何时候都能正确的生成ID。
- 带时间:ID里面包含时间,一眼扫过去就知道哪天的交易。
系统时间毫秒数
我们可以使用当前系统时间精确到毫秒数+业务属性+用户属性+随机数+…等参数组合形式来确保ID的唯一性,缺点是ID的有序性难以保证,要保证有序性就要依赖数据库或者其他中间存储媒介。
UUID
Java自带的生成UUID的方式就能生成一串唯一随机32位长度数据,而且够我们用N亿年,保证唯一性肯定是不用说的了,但缺点是它不包含时间、业务数据可读性太差了,而且也不能ID的有序递增。
这是一种简单的生成方式,简单,高效,但在一般业务系统中我还没见过有这种生成方式。
数据库自增ID
我们都知道为数据库主键设置自增序号,以一定的趋势自增,以保证主键ID的唯一性。
这个方案很简单,但最主要的问题在于依赖数据库本身,这就无形增加了对数据库的访问压力和依赖,一旦对单库进行分库分表或者数据迁移就尴尬了。
所以,这也不是合适的ID生成方法。
批量生成ID
一次按需批量生成多个ID,每次生成都需要访问数据库,将数据库修改为最大的ID值,并在内存中记录当前值及最大值。这样就避免了每次生成ID都要访问数据库并带来压力。
这种方案服务就是单点了,如果服务重启势必会造成ID丢失不连续的情况,而且这种方式也不利于水平扩展。
中间件
Redis的所有命令操作都是单线程的,本身提供像incr这样的自增命令,所以能保证生成的ID肯定是唯一有序的。
这种方式不依赖关系数据库,而且速度快。但系统要引入Redis这一中间件,增加维护成本,而且编码和配置工作量比较大。即使已经有了Redis组件,但生成ID的高频率访问对单线程的Redis性能势必也会造成影响。
还可以利用像Zookeeper中的znode数据版本来生成序列号,及MongoDB的ObjectId等,这种利用中间件的做法不是很推荐。
snowflake算法
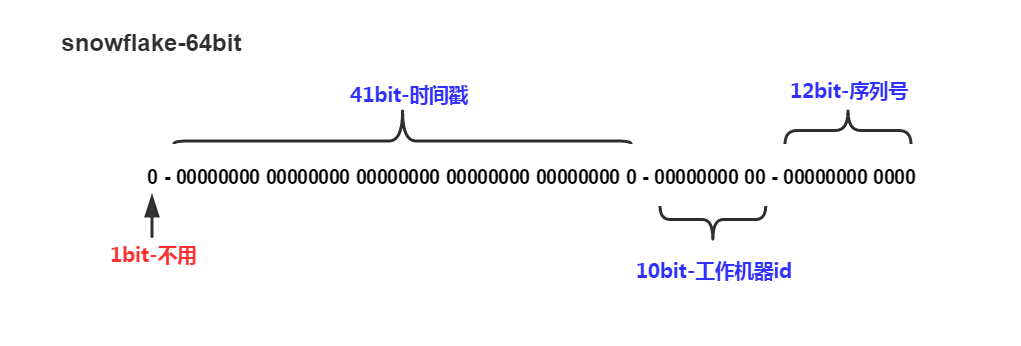
如上图的所示,Twitter的snowflake算法下面几部分组成:
- 41位的时间序列,精确到毫秒,可以使用69年
- 10位的机器标识,最多支持部署1024个节点
- 12位的序列号,支持每个节点每毫秒产生4096个ID序号,最高位是符号位始终为0。
这种方案性能好,在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
而且这个项目在2010就停止维护了,但这个设计思路还是应用于其他各个ID生成器及变种。
UidGenerator
UidGenerator是百度开源的分布式ID生成器,基于于snowflake算法的实现,看起来感觉还行。不过,国内开源的项目维护性真是担忧。
大家可以参考具体使用:
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
Leaf
Leaf是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。
具体可以参考官网说明:
https://tech.meituan.com/MT_Leaf.html
好了,就这么多了,不同的方案应用的场景和系统也是不同的。大家有更好的方案也可以在下面留言,一起讨论下大家都是怎么做的。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。