大家好,我是栈长。
昨天 17 点多,栈长兴致来了,忙里偷闲正在看了一把 LOL S13 淘汰赛,没想到比赛还没看完朋友圈就已经炸锅了:
朋友圈有人开玩笑说,阿里 35 岁的人是不是都被优化了?还是双 11 后都松懈了?这大周末的还让加班?让不让人省心点。。
这我看完也有点懵 B ,大家还记得上次的语雀重大故障吧,弄了近 8 小时才完全恢复,这刚过去 10 来天,又来?这不是像阿里这样的大厂该有的作为啊!!

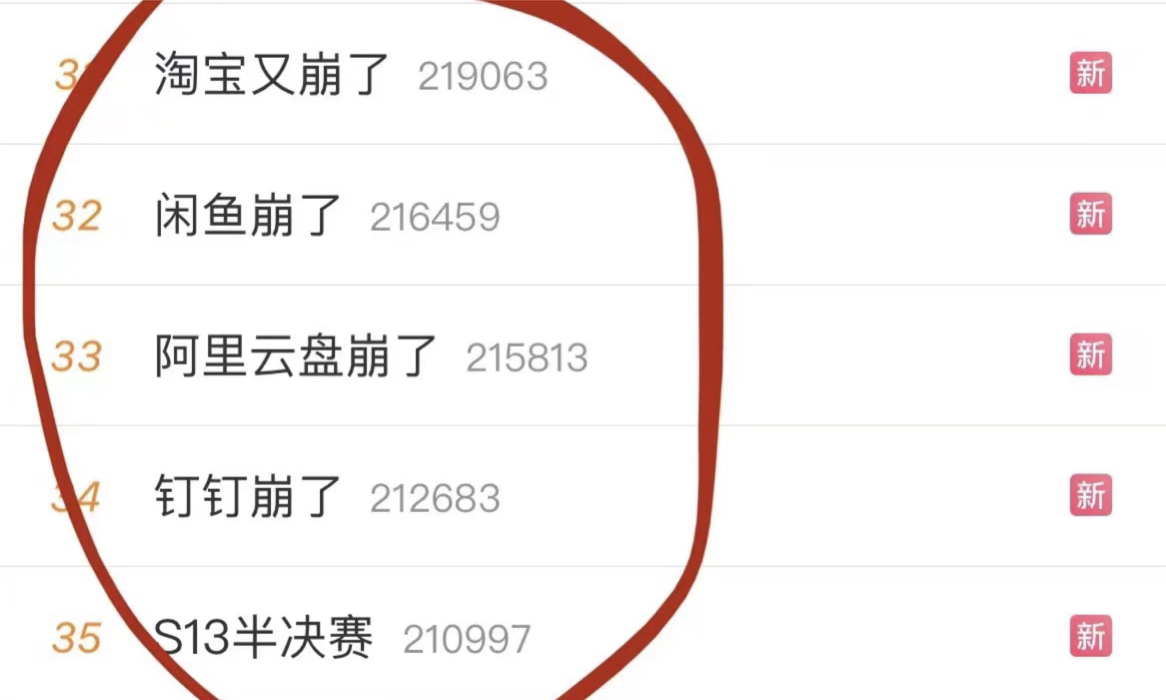
这次影响的还不只是语雀,阿里系大部分产品都受到影响,包括:淘宝、阿里云、钉钉、语雀、闲鱼、阿里云盘……

好家伙,一堆产品都上了微博热搜,热度甚至盖过了 S13 半决赛。。
说到 LOL,这比赛都打的啥啊,太无语了,我上我也行,就这状态,看得太失望了。
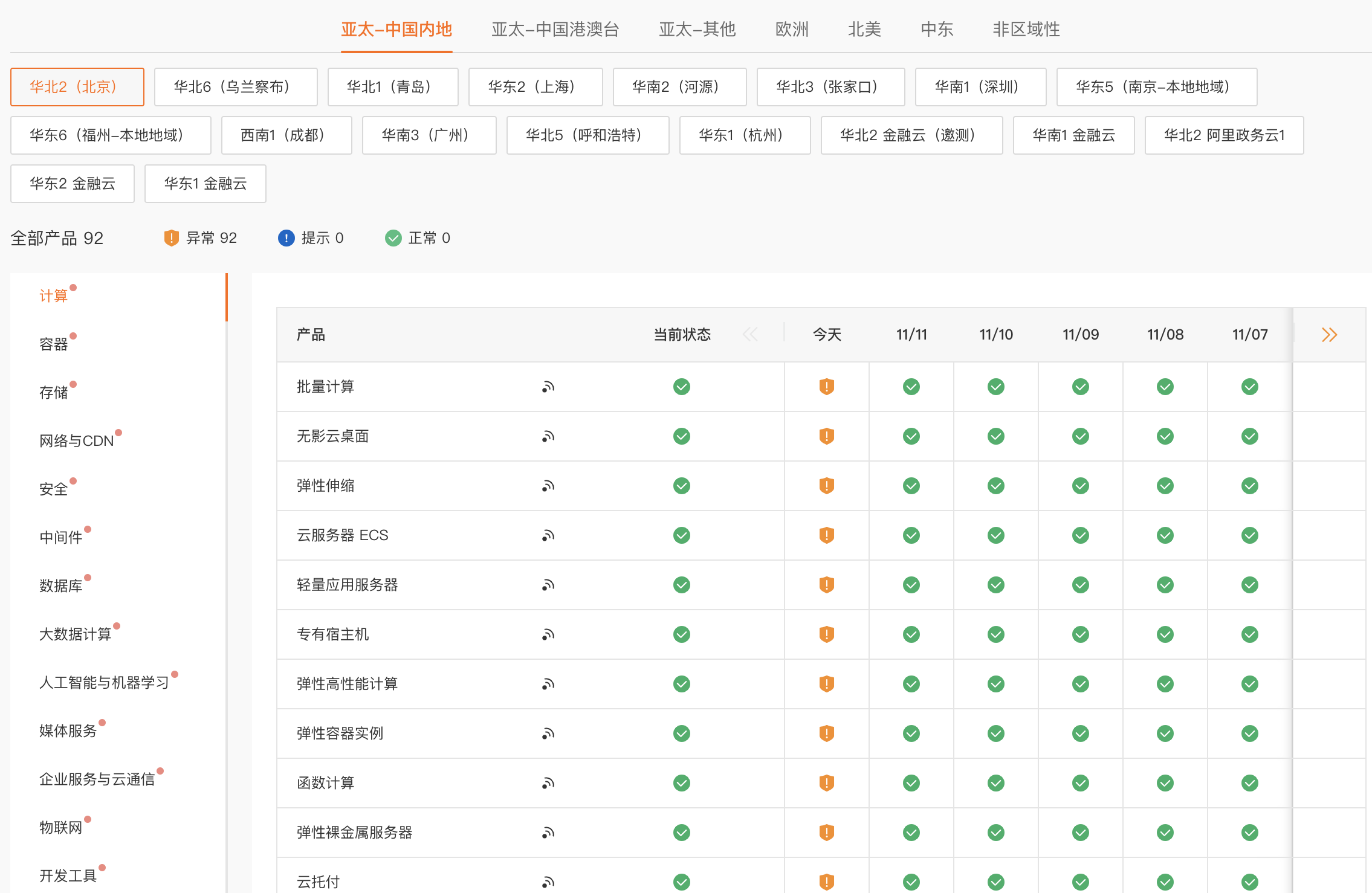
其他影响倒还好,阿里云众多产品都受到了故障影响。。。

LOL 都看完了还没有完全恢复,直到晚上 21:11 分所有云产品才基本恢复正常:

阿里云确认故障原因与某个底层服务组件有关,这么大个故障,居然都没做好各种测试?我也是大写的服!这次故障后,这位运维同学、总监的年终奖怕是没有了。
阿里云服务状态查询网站:
栈长写文时,阿里云服务显示已恢复正常:
说到云服务器,为了提升企业开发和运营效率,不少公司都会选择云服务器,相信这次事件会给不少使用云服务器的人敲响警钟。
我个人也用云服务器,包括小程序:Java面试库、博客网站、各种课程的后台系统等,都会用到云服务器,期间也出现过服务中断的情况,也有惨痛的、折腾死我的情况,所以,为了用户体验,我做任何操作都十分谨慎。。
为了服务稳定性,我总结了以下几个要点:
1、数据备份
不要相信任何平台,数据不在你手里,就不是你的,可能随时找不回,所以,如果要使用云产品,养成定时备份数据的习惯是非常重要的。
数据备份可以是这样:
- 使用高可用的云产品;
- 定期对系统盘备份镜像;
- 做任何敏感运维操作都提前对系统备份镜像;
- 每天对数据盘进行快照;
- 手动备份重要数据到其他安全的地方;
- ……
2、多云策略
不要全部依赖单一云服务提供商,一个平台出现故障,即使是高可用也是无解。可以考虑分布式部署,比如将一部分服务放在阿里云,另一部分放在腾讯云或其他云,这样不至于阿里云故障导致所有服务不可用。
其他云产品也是如此,鸡蛋不要放在一个篮子里。
3、镜像环境 + 灰度发布
可以做一个镜像环境,和线上环境一模一样,系统上线时先在镜像环境上线,如测试没事再在线上环境进行灰度发布,这也不至于影响所有用户吧?
4、应急预案
不管怎么样,处理紧急意外情况的预案还要是有的,提前制定好详细的应急预案,包括数据备份、紧急切换到备用系统等,做好全方位的监控,确保在系统服务中断时,业务能迅速恢复,从而不影响到业务。
所以,要做好应急预案,随时可以回滚,能迅速恢复服务,这是非常重要的,长时间折腾故障分析故障原因对真的不可取,这对企业和用户来说都是灾难。
说说感受:
阿里这个重大故障,就这事确实挺夸张的,我个人也挺想不通,阿里是国内的龙头 IT 大厂,这么大个企业,这么多产品受到这么长时间的故障影响,还一而再再而三的出现重大事故,真的会让不少人失去信心。
云服务器还受这么长时间影响,更不应该啊,想想全中国有多少企业和开发者都在用,任何一个小故障可能都会导致大量企业业务中断,造成重大损失,甚至使公司倒闭。
大家还记得,之前有一家以数据为生存的公司因为云服务器故障导致数据全部丢失的事件吧,数据全丢了,结果公司也倒闭了,所以,记住,鸡蛋不要放在一个篮子里,记得定期对数据进行备份。
上次语雀重大故障,大家都领到了 6 个月的会员补偿,这次截止栈长写文时,我并没有在看到有类似的补偿。当然,补偿不是目的,只能安抚人心,我们希望云产商做好服务稳定是首要的,不要让大家对云服务器提心吊胆。
最后,鸡蛋不要放在同一个篮子里!!!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



