
大家好,我是R哥。
前几天,一个同学跟我说,他去鹅厂面试,面试官问他:
RAG 是什么?为什么要用它?直接调用大模型生成回复不行吗?
这位同学一听,连忙回答:
RAG 就是先检索,再生成。先从知识库里找资料,再把资料和问题一起丢给大模型,让大模型回答。
面试官听完点点头,又追问了一句:
那为什么不直接让大模型回答?大模型不是已经很强了吗?
这一下,他有点被卡住了。。
为什么需要 RAG?
其实这个问题的关键,不是解释 RAG 的流程,而是要讲清楚一件事:
RAG 解决的从来不是生成问题,而是知识来源问题。
大模型本身是很强,它很会组织语言,很会总结、推理、改写、归纳。
但它最大的问题是:
- 它不知道它没见过的东西。
- 它也不知道你公司内部的东西。
- 它更不知道今天刚发生的东西。
大语言模型虽然知识面广,但它的知识是训练时就固化的,比如 GPT-4 截止知识可能是 2024 年甚至更前。
如果你问它:
请告诉 XX 公司 2026 年的假期安排?
它回答不了,因为这些是实时、私有、公司内的知识,模型根本没见过。所以,一旦问题涉及实时信息、私有知识等,就不能只靠大模型自己发挥了。
这时就需要 RAG 技术登场了,RAG 能结合外部知识检索和大模型生成能力,提升模型在特定领域的问题回答能力。
什么是 RAG?
RAG,全称是 Retrieval-Augmented Generation,即 “检索增强生成”,它是目前在大模型应用中非常重要的一种技术,特别适用于问答、文档总结、知识问答机器人、企业知识库接入等场景。
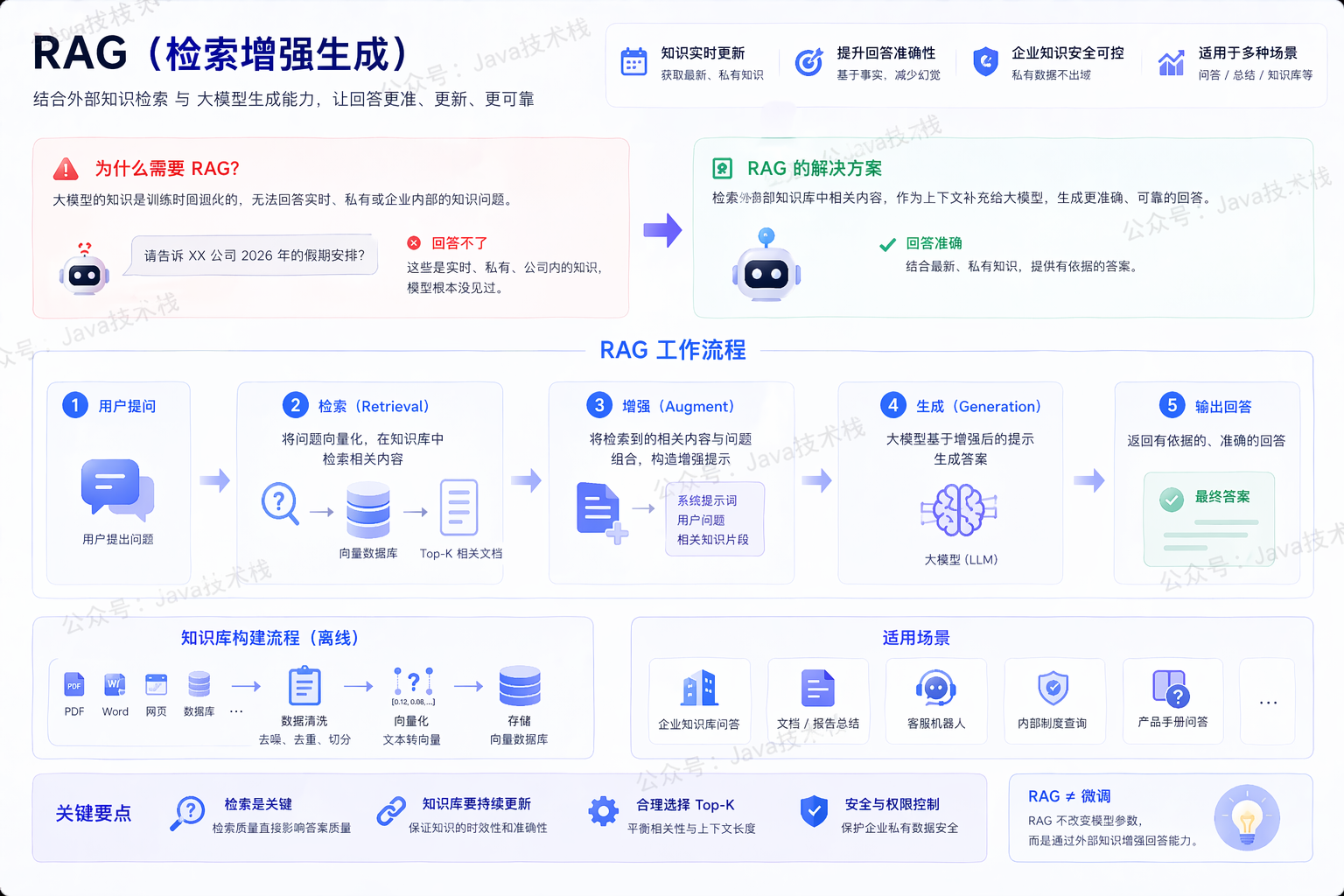
RAG 拆开来看,其实就两个动作:
- 第一步:检索(Retrieval):系统先从企业文档库/数据库/知识库中查找相关资料(比如用向量检索、全文检索等技术)。
- 第二步:生成(Generation):把这些检索到的内容 + 你的问题,一起发给大模型,由大模型综合生成回答。
如图所示:

RAG 就是在用户提问的时候,动态把相关知识找出来,再塞给大模型。所以,RAG 不是替代大模型,而是给大模型补知识。
RAG 的意义,就是让大模型少一点自由发挥,多一点事实依据。
大模型负责理解问题、整合信息、生成自然语言,检索系统负责找到可信、相关、及时的知识,两者配合起来,才适合做真正可落地的 AI 应用。
回到开头那个面试问题:
RAG 是什么?为什么要用它?直接调用大模型生成回复不行吗?
比较好的回答可以这么说:
RAG 是检索增强生成,它的核心流程是先从外部知识库中检索和用户问题相关的内容,再把这些内容作为上下文交给大模型生成答案。
它解决的重点不是生成能力问题,而是知识来源问题。
大模型本身有很强的语言理解和生成能力,但它的知识来自训练数据,存在知识截止、私有知识缺失、实时信息缺失、容易幻觉、答案不可追溯等问题。
直接调用大模型时,如果问题属于通用知识或者文本处理任务,一般没问题,但如果问题涉及企业内部数据,就不能让模型凭空回答。
RAG 通过检索外部知识,把相关资料动态提供给模型,让模型基于资料回答,从而提升准确性、时效性和可追溯性。
在企业落地里,RAG 一般包含文档解析、文本切分、 Embedding、向量数据库、召回、重排序、提示词构建、大模型生成等环节。
同时还要注意知识库治理、权限控制、切分策略、混合检索、引用来源和效果评估。
当然,RAG 也不是银弹,它对知识库质量、检索效果、权限控制、提示词设计、评估体系都有要求。
想做好 RAG,不是接个向量数据库、调个大模型接口就完事了,而是要把知识工程、搜索工程和大模型工程结合起来。
最后,认真推荐下我的《Spring AI 开发实战课 》,学完把它落地到真实项目里,出去面试的时候就有竞争力了,很多面试官都不一定会,你能落地应用,能说上来,可以和其他同学直接拉开差距了。
Spring AI 2.0 发布后,Java AI 真正要起飞了。。
Spring AI 让 Java 再次伟大!!
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



