写在前面
Java的基类Object提供了一些方法,其中equals()方法用于判断两个对象是否相等,hashCode()方法用于计算对象的哈希码。equals()和hashCode()都不是final方法,都可以被重写(overwrite)。
本文介绍了2种方法在使用和重写时,一些需要注意的问题。
equal()方法
Object类中equals()方法实现如下:
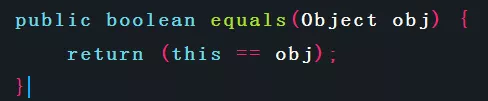
通过该实现可以看出,Object类的实现采用了区分度最高的算法,即只要两个对象不是同一个对象,那么equals()一定返回false。
虽然我们在定义类时,可以重写equals()方法,但是有一些注意事项;JDK中说明了实现equals()方法应该遵守的约定:
1)自反性:x.equals(x)必须返回true。
2)对称性:x.equals(y)与y.equals(x)的返回值必须相等。
3)传递性:x.equals(y)为true,y.equals(z)也为true,那么x.equals(z)必须为true。
4)一致性:如果对象x和y在equals()中使用的信息都没有改变,那么x.equals(y)值始终不变。
5)非null:x不是null,y为null,则x.equals(y)必须为false。
hashCode()方法
1、Object的hashCode()

可以看出,hashCode()是一个native方法,而且返回值类型是整形;实际上,该native方法将对象在内存中的地址作为哈希码返回,可以保证不同对象的返回值不同。
与equals()方法类似,hashCode()方法可以被重写。JDK中对hashCode()方法的作用,以及实现时的注意事项做了说明:
1)hashCode()在哈希表中起作用,如java.util.HashMap。
2)如果对象在equals()中使用的信息都没有改变,那么hashCode()值始终不变。
3)如果两个对象使用equals()方法判断为相等,则hashCode()方法也应该相等。
4)如果两个对象使用equals()方法判断为不相等,则不要求hashCode()也必须不相等;但是开发人员应该认识到,不相等的对象产生不相同的hashCode可以提高哈希表的性能。
2、hashCode()的作用
总的来说,hashCode()在哈希表中起作用,如HashSet、HashMap等。
当我们向哈希表(如HashSet、HashMap等)中添加对象object时,首先调用hashCode()方法计算object的哈希码,通过哈希码可以直接定位object在哈希表中的位置(一般是哈希码对哈希表大小取余)。如果该位置没有对象,可以直接将object插入该位置;如果该位置有对象(可能有多个,通过链表实现),则调用equals()方法比较这些对象与object是否相等,如果相等,则不需要保存object;如果不相等,则将该对象加入到链表中。
这也就解释了为什么equals()相等,则hashCode()必须相等。如果两个对象equals()相等,则它们在哈希表(如HashSet、HashMap等)中只应该出现一次;如果hashCode()不相等,那么它们会被散列到哈希表的不同位置,哈希表中出现了不止一次。
实际上,在JVM中,加载的对象在内存中包括三部分:对象头、实例数据、填充。其中,对象头包括指向对象所属类型的指针和MarkWord,而MarkWord中除了包含对象的GC分代年龄信息、加锁状态信息外,还包括了对象的hashcode;对象实例数据是对象真正存储的有效信息;填充部分仅起到占位符的作用, 原因是HotSpot要求对象起始地址必须是8字节的整数倍。可以点击此处查看更多解析JVM内存解析。
String中equals()和hashCode()的实现
String类中相关实现代码如下:
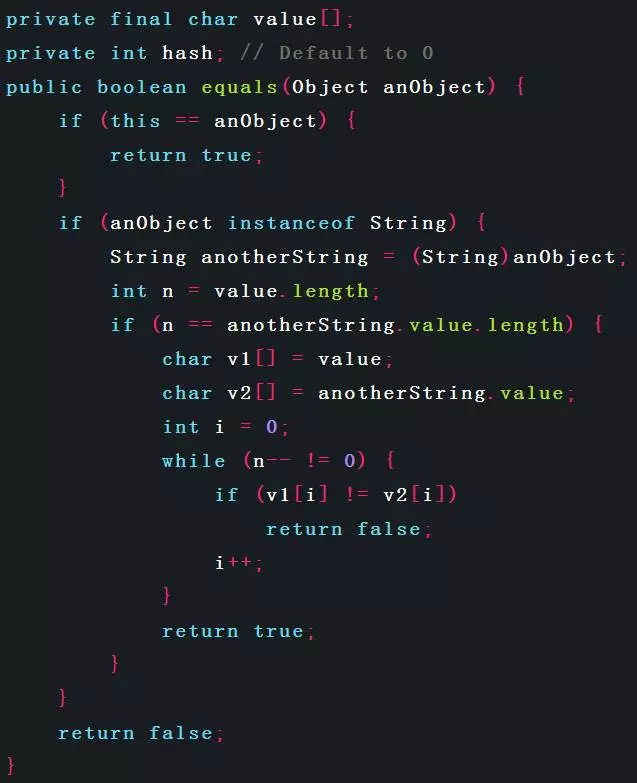
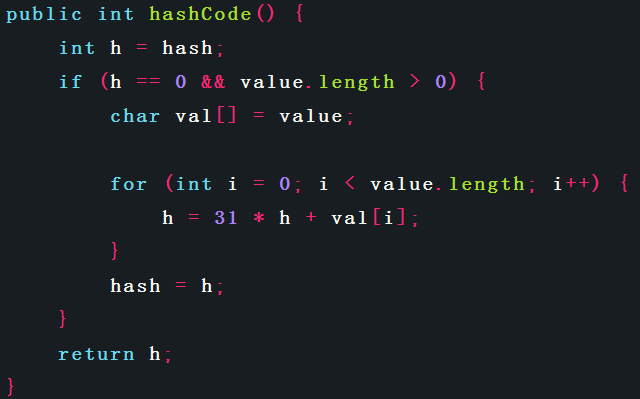
通过代码可以看出以下几点:
1、String的数据是final的,即一个String对象一旦创建,便不能修改;形如String s = “hello”; s = “world”;的语句,当s = “world”执行时,并不是字符串对象的值变为了”world”,而是新建了一个String对象,s引用指向了新对象。
2、String类将hashCode()的结果缓存为hash值,提高性能。
3、String对象equals()相等的条件是二者同为String对象,长度相同,且字符串值完全相同;不要求二者是同一个对象。
4、String的hashCode()计算公式为:s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]
关于hashCode()计算过程中,为什么使用了数字31,主要有以下原因:
1)使用质数计算哈希码,由于质数的特性,它与其他数字相乘之后,计算结果唯一的概率更大,哈希冲突的概率更小。
2)使用的质数越大,哈希冲突的概率越小,但是计算的速度也越慢;31是哈希冲突和性能的折中,实际上是实验观测的结果。
3)JVM会自动对31进行优化:31 * i == (i << 5) – i
如何重写hashCode()
本节先介绍重写hashCode()方法应该遵守的原则,再介绍通用的hashCode()重写方法。
1、重写hashcode()的原则
通过前面的描述我们知道,重写hashCode需要遵守以下原则:
1)如果重写了equals()方法,检查条件“两个对象使用equals()方法判断为相等,则hashCode()方法也应该相等”是否成立,如果不成立,则重写hashCode ()方法。
2)hashCode()方法不能太过简单,否则哈希冲突过多。
3)hashCode()方法不能太过复杂,否则计算复杂度过高,影响性能。
2、hashCode()重写方法
《Effective Java》中提出了一种简单通用的hashCode算法
A、初始化一个整形变量,为此变量赋予一个非零的常数值,比如int result = 17;
B、选取equals方法中用于比较的所有域(之所以只选择equals()中使用的域,是为了保证上述原则的第1条),然后针对每个域的属性进行计算:
1) 如果是boolean值,则计算f ? 1:0;
2) 如果是byte\char\short\int,则计算(int)f;
3) 如果是long值,则计算(int)(f ^ (f >>> 32));
4) 如果是float值,则计算Float.floatToIntBits(f);
5) 如果是double值,则计算Double.doubleToLongBits(f),然后返回的结果是long,再用规则(3)去处理long,得到int;
6) 如果是对象应用,如果equals方法中采取递归调用的比较方式,那么hashCode中同样采取递归调用hashCode的方式。否则需要为这个域计算一个范式,比如当这个域的值为null的时候,那么hashCode 值为0;
7) 如果是数组,那么需要为每个元素当做单独的域来处理。java.util.Arrays.hashCode方法包含了8种基本类型数组和引用数组的hashCode计算,算法同上。
C、最后,把每个域的散列码合并到对象的哈希码中。
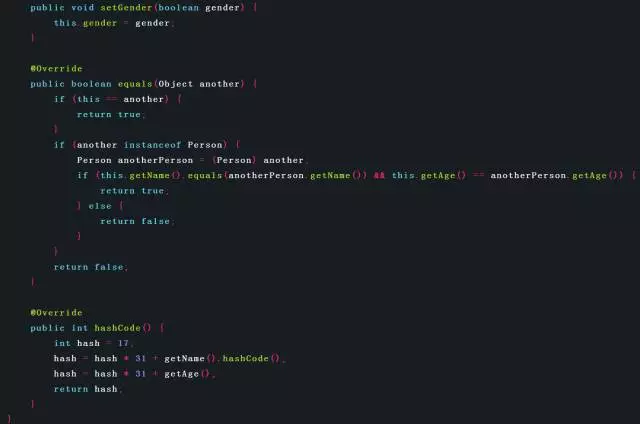
下面通过一个例子进行说明。在该例中,Person类重写了equals()方法和hashCode()方法。因为equals()方法中只使用了name域和age域,所以hashCode()方法中,也只计算name域和age域。
对于String类型的name域,直接使用了String的hashCode()方法;对于int类型的age域,直接用其值作为该域的hash。

来源:http://www.importnew.com/25783.html
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。