大家好,我是R哥。
最近 AI 编程模型又卷疯了。
一边是国外大模型继续往工程能力、长上下文、Agent 方向猛冲,另一边是国产模型也开始发力,各种大模型宣称能媲美 Claude 的能力。。
所以现在再问哪个编程模型最强,其实已经不太好回答了,因为不同模型的性格差异越来越明显了。
有的适合写复杂工程,有的适合做 UI,有的适合改老项目,有的适合跑 Agent,有的 benchmark 很漂亮,但真正干活的时候可能又是另外一个样子。
我这篇就不做学术排名了,只聊真实编程体感。。

第一梯队(夯爆)
第一梯队我觉得就是两个:GPT 5.5 和 Claude Opus 4.6 / 4.7,毫无疑问,这两个基本属于双王并列。没有绝对第一,只有场景适配。
GPT 5.5 的优势是综合、全面,工程场景也很稳。
尤其是 API 生态、工具链适配、工程落地这一块,搭配 Codex CLI、Codex APP、云端支持,这一套确实成熟,它可能不是最牛逼的,但是全方面能力最强的。
而且 GPT 5.5 的性价比也很能打,如果你是高频使用,比如每天写文案、写代码、生成图片等工作,Plus 就完全能够胜任,它属于那种量大管饱型选手。
当然,它缺点也有。
它写界面的审美还需要继续打磨,功能上能完成,但 UI 有时候会有点程序员审美,能用,规整,但少一点产品感和高级感。
Claude Opus 4.6 / 4.7 则是另一种强。
它的上下文理解很强(1M),尤其适合产品逻辑、复杂需求、长文档、UI 交互这类任务。
在实际编程时,你都不用把每个细节都说死,它能顺着你的意图往下补,甚至能提前想到一些你没说但确实需要的东西。
这就是 Claude 最厉害的地方,它不是只会写代码,它更像懂产品的人在帮你写代码。
缺点就是:贵、对网络环境要求非常高、非常容易封号,前阵子又搞出了实名认证,用 Claude 的成本是越来越高,也越来越不可控。
参考阅读:
就 Claude 种种变态的限制行为,建议大家还是还是不要作为首选或者太依赖它。
第二梯队(夯)
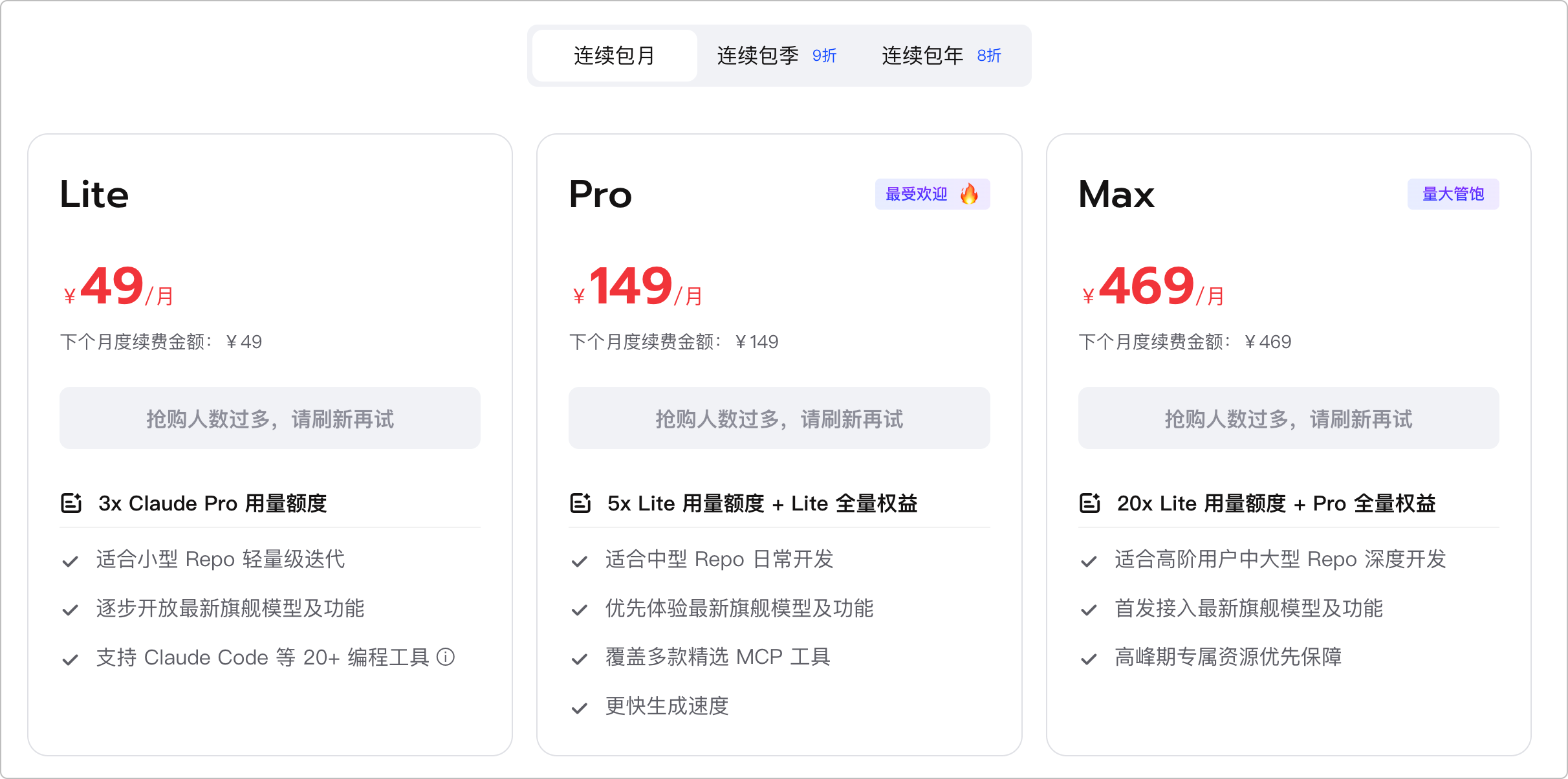
第二梯队也很有意思,比如:GLM-5.1、Gemini 3、Qwen 3、DeepSeek V4、Kimi K2.6 这些大模型就在这一档。
先说 GLM-5.1,目前最接近第一梯队的国产模型之一。
尤其是 Agent 能力,已经能贴着第一梯队打了。它不是那种只会回答问题的聊天模型,而是已经开始具备拆任务、调工具、持续推进的高级能力。
但它的问题也明显:慢,而且不够稳定,算力不够,订阅非常难,Coding Plan 基本都要靠抢。
再说说 Gemini 3,它是典型的偏科生。
它在 UI 和前端场景挺能打,尤其是页面布局、视觉表达、交互结构,经常能给你一些不错的结果。做页面时,它有时候比传统工程型模型更有感觉。
但工程场景偏弱,比如:复杂后端、长链路重构、多模块项目协同,它没有 GPT 和 Claude 那么稳。
所以 Gemini 的定位很清楚,适合前端、UI、视觉类任务,复杂工程尽量别用它。
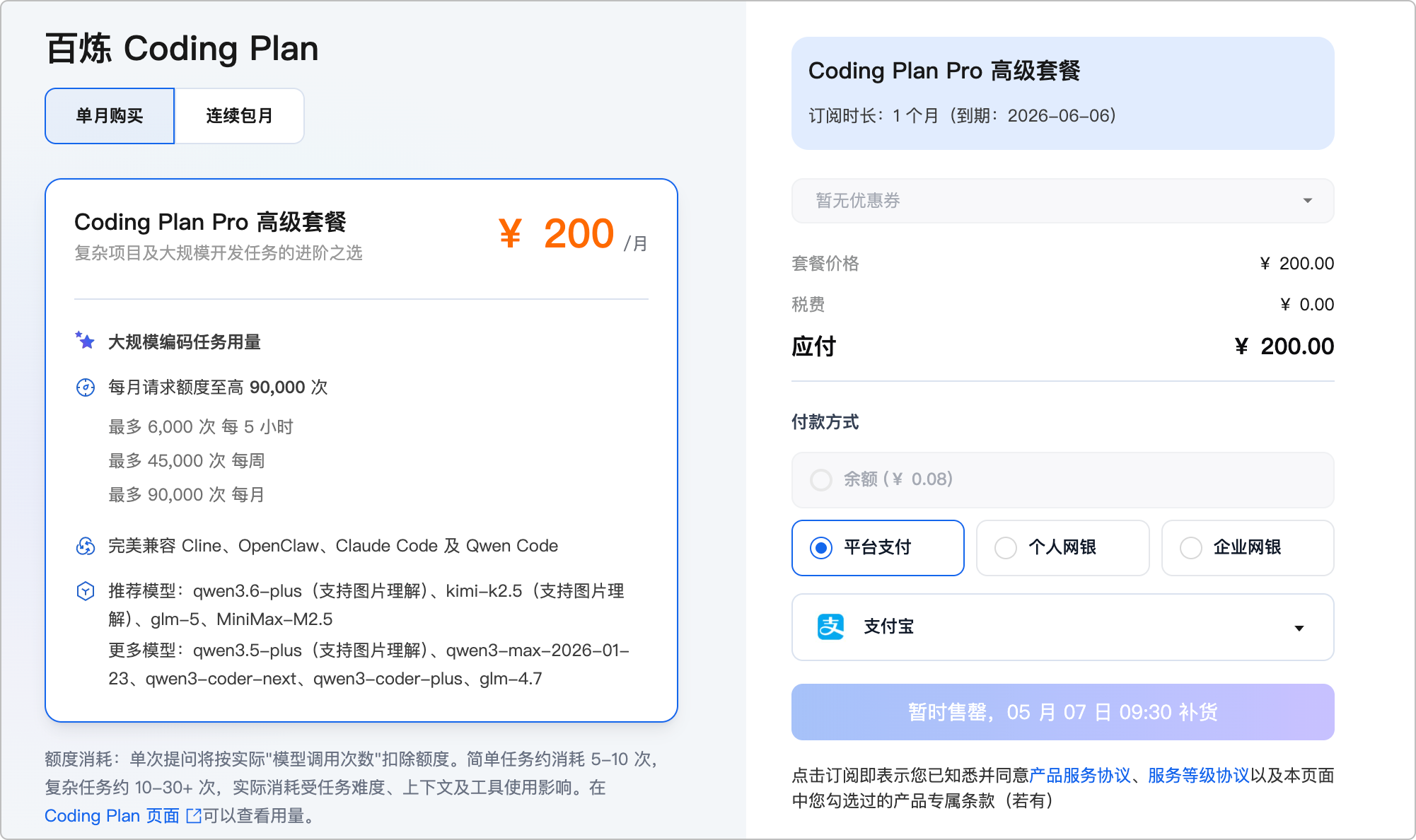
再说说通义千问 Qwen 3,它属于国产里非常能打的一档。
它的整体能力比较均衡,一般来说在代码生成、中文理解、工程任务上表现都比较稳定,比如写接口、补代码、做业务逻辑这类活都能很好胜任。
而且它的优势在于生态完整 + 落地能力强,依托阿里云,在企业应用、API 接入、私有化部署等场景里会更有优势。
但问题也有,一般来说在复杂工程推理、长上下文深度理解上,和第一梯队还是有差距。
另外,它也是一样的套路,Coding Plan 基础款已经下线,高级套餐订阅还要靠抢。。
再说说 DeepSeek V4,它写代码比较稳重。
很多模型写代码喜欢加戏,明明你只要改一个地方,它顺手给你重构一大片。DeepSeek 的风格一般更收敛,常规业务代码写得快,也不太乱发挥。
它适合程序员日常开发里的大量基础活,比如 CRUD、脚本、接口逻辑、工具类、常见算法,它都挺稳。
但它的问题是,目前没有 Coding Plan,如果拿来高频编程,成本会显得有点高。
最后再说说 Kimi K2.6,它属于潜力型选手。
它的 benchmark 很出色,Coding Plan 也不用抢,但实际用下来,体感有时没那么丝滑,尤其是复杂工程任务里,它有时会在执行过程中掉一下链子。
感觉它很适合龙虾这么类 Agent,之前还上过最适合 OpenClaw 大模型的榜单。
所以我对 Kimi 的评价是,上限很高,但稳定性还需要时间。
怎么选?
我建议别只用一个模型,而是更合理的组合使用:
- 写后端、修 bug、处理工程任务,用 GPT 5.5。
- 做复杂产品设计、需求梳理,用 Claude 4.7。
- 做前端页面和视觉草稿,可以让 Gemini 3 先跑一版。
- 想体验国产大模型能力,可以试 GLM-5.1、Qwen 3。
- 想写稳定业务代码,可以用 DeepSeek V4。
组合搭配,这样才是目前更实际的玩法,我目前也是这么玩的。
因为模型之间已经不是简单的谁强谁弱,而是各方面能力各不不同,就像团队里有人适合做架构,有人适合写页面,有人适合修线上问题,有人适合写文档。
你非要让一个大模型干所有活,也不是不行,就是效率、质量等方面可能不一定是最高的。
当然,也可以根据自己的任务进行测试,一般简单的任务你随便用哪个可能区别都不大,复杂任务还得是用最专业的、最夯的模型。
好了,今天就暂时分享到这里了,R哥持续分享更多 AI 好玩的东西,公众号第一时间推送,关注「AI技术宅」公众号和我一起学 AI。
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



