一.分分合合
说过很多次,不要拘泥于某一个技术的一点,技术是相通的。重要的是编程思想,思想是最重要的。
当数据量大的时候,需要具有分的思想去细化粒度。当数据量太碎片的时候,需要具有合的思想来粗化粒度。
1.1 分
很多技术都运用了分的编程思想,这里来举几个例子,这些都是分的思想
-
集中式服务发展到分布式服务
-
从Collections.synchronizedMap(x)到1.7ConcurrentHashMap再到1.8ConcurrentHashMap,细化锁的粒度的同时依旧保证线程安全
-
从AtomicInteger到LongAdder,ConcurrentHashMap的size()方法。用分散思想,减少cas次数,增强多线程对一个数的累加
-
JVM的G1 GC算法,将堆分成很多Region来进行内存管理
-
Hbase的RegionServer中,将数据分成多个Region进行管理
-
平时开发是不是线程池都资源隔离
2.2 合
很多技术也运用到了合的编程思想,这里举几个例子,这些都是合的思想
-
TLAB(Thread Local Allocation Buffers),线程本地分配缓存。避免多线程冲突,提高对象分配效率
-
逃逸分析,将变量的实例化内存直接在栈里分配,无需进入堆,线程结束栈空间被回收。减少临时对象在堆内分配数量
-
CMS GC算法下,虽然使用标记清除,但是也有配置支持整理内存碎片。如:-XX:UseCMS-CompactAtFullCollection(FullGC后是否整理,Stop The World会变长)和-XX:CMSFullGCs-BeforeCompaction(几次FullGC之后进行压缩整理)
-
锁粗化,当JIT发现一系列连续的操作都是对同一对象反复加锁和释放锁,会加大锁同步的范围
-
kafka的网络数据传输有一些数据配置,减少网络开销。如:batch.size和linger.ms等等
-
平时开发是不是都个叫批量获取接口
二.分区
本文一切基于MySql InnoDB
说了这么多,接下来说主体,先说分区,因为之前博主写过一篇MySql分区的博客所以这里不会多费笔墨来写,具体见:一文带你搞懂 MySQL 中的分区!
2.1 实现方式
具体如何实现上面链接里有写,这里只需记住如果表中存在主键或唯一索引时,分区列必须是唯一索引的一个组成部分。
这个是数据库分的,应用透明,代码无需修改任何东西。
2.2 内部文件
先去data目录,如果不知道目录位置的可以执行:
接下来看下内部文件:
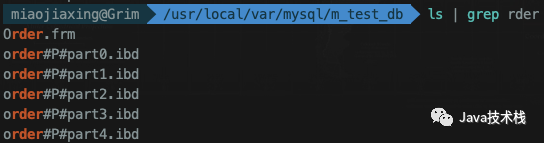
从上图我们可以看出,有2中类型的文件,.frm文件和.ibd文件
-
.frm文件:表结构文件
-
.ibd文件:InnoDB中,索引和数据都在同个文件.ibdata(你的执行结果可能是.MYD索引文件和.MYI数据文件,没关系,这是MyIsAm存储引擎,对应着InnoDB的.ibd文件)。因为Order这张表分为5个区,所以有5个这样的文件
-
.par文件:你执行的结果可能有.par文件也可能没有。注意:从MySql 5.7.6开始,不再创建.par分区定义文件。分区定义存储在内部数据字典中。
2.3 数据处理
分区表后,提高了MySql性能。如果一张表的话,那就只有一个.ibd文件,一颗大的B+树。如果分表后,将按分区规则,分成不同的区,也就是一个大的B+树,分成多个小的树。
读的效率肯定提升了,如果走分区键索引的话,先走对应分区的辅助索引B+树,再走对应分区的聚集索引B+树。
如果没有走分区键,将会在所有分区都会执行一次。会造成多次逻辑IO!
平时开发如果想查看sql语句的分区查询可以使用explain partitons select xxxxx语句。可以看到一句select语句走了几个分区。
mysql> explain partitions select * from TxnList where startTime>'2016-08-25 00:00:00' and startTime<'2016-08-25 23:59:00';
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra |
| 1 | SIMPLE | ClientActionTrack | p20160825 | ALL | NULL | NULL | NULL | NULL | 33868 | Using where |
row in set (0.00 sec)
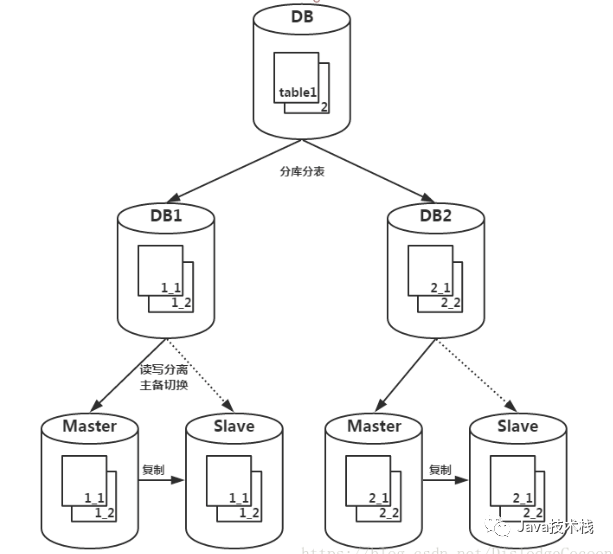
三.分库分表
当一张表随着时间和业务的发展,库里表的数据量会越来越大。数据操作也随之会越来越大。
一台物理机的资源有限,最终能承载的数据量、数据的处理能力都会受到限制。这时候就会使用分库分表来承接超大规模的表,单机放不下的那种。
区别于分区的是,分区一般都是放在单机里的,用的比较多的是时间范围分区,方便归档。只不过分库分表需要代码实现,分区则是mysql内部实现。分库分表和分区并不冲突,可以结合使用。
3.1 实现
3.1.1 分库分表标准
-
存储占用100G+
-
数据增量每天200w+
-
单表条数1亿条+
3.1.2 分库分表字段
分库分表字段取值非常重要
-
在大多数场景该字段是查询字段
-
数值型
一般使用userId,可以满足上述条件
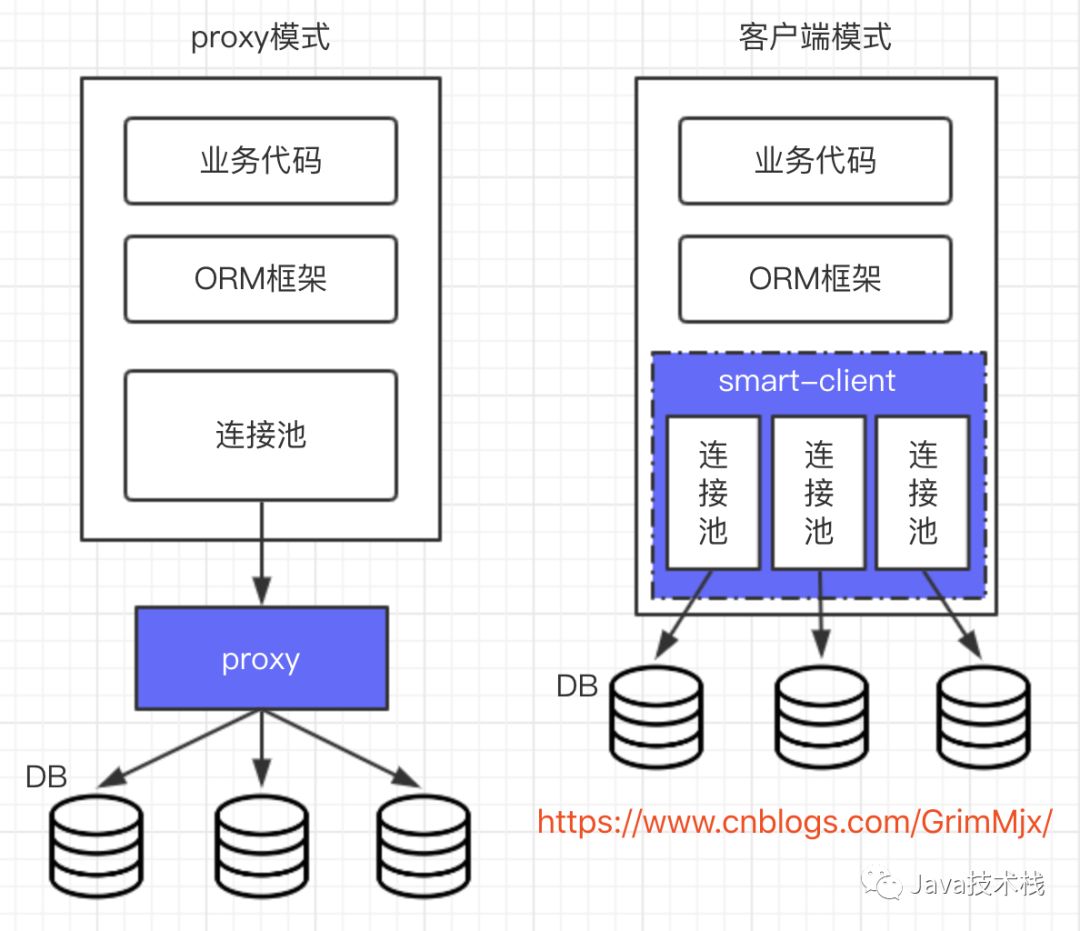
3.2 分布式数据库中间件
分布式数据库中间件分为两种,proxy和客户端式架构。proxy模式有MyCat、DBProxy等,客户端式架构有TDDL、Sharding-JDBC等。
那么proxy和客户端式架构有何区别呢?各自有什么优缺点呢?其实看一张图便可知晓。
proxy模式的话我们的select和update语句都是发送给代理,由这个代理来操作具体的底层数据库。所以必须要求代理本身需要保证高可用,否则数据库没有宕机,proxy挂了,那就走远了。
客户端模式通常在连接池上做了一层封装,内部与不同的库连接,sql交给smart-client进行处理。通常仅支持一种语言,如果其他语言要使用,需要开发多语言客户端。
各自的优缺点如下:

3.3 内部文件
找了一个分库分表+分区的例子,基本上和分区表的差不多,只是多了多了很多表的.ibd文件,上面有文件的解释:
\[miaojiaxing@Grim testmydata\]# ls | grep 'base_info'
base\_info\_00.frm
base\_info\_00#P#p_2018.ibd
base\_info\_00#P#p_2019.ibd
base\_info\_00#P#p_2020.ibd
base\_info\_00#P#p_2021.ibd
base\_info\_00#P#p_init.ibd
base\_info\_00#P#p_max.ibd
base\_info\_01.frm
base\_info\_01#P#p_2018.ibd
base\_info\_01#P#p_2019.ibd
base\_info\_01#P#p_2020.ibd
base\_info\_01#P#p_2021.ibd
base\_info\_01#P#p_init.ibd
base\_info\_01#P#p_max.ibd
base_info.frm
base_info.ibd
3.4 问题
3.4.1 事务问题
既然分库分表了,那么肯定涉及到分布式事务,如何保证插入到不同库的多条记录能够要么同时成功,要么同时失败。
有些同学可能想到XA,XA性能差而且不需要使用mysql5.7。柔性事务是目前主流的方案,TCC模式就属于柔性事务。
对于分布式事务问题每家公司有自己的实现,华为用saga,阿里用TXC,蚂蚁用DTX,支持FMT模式和TCC模式。
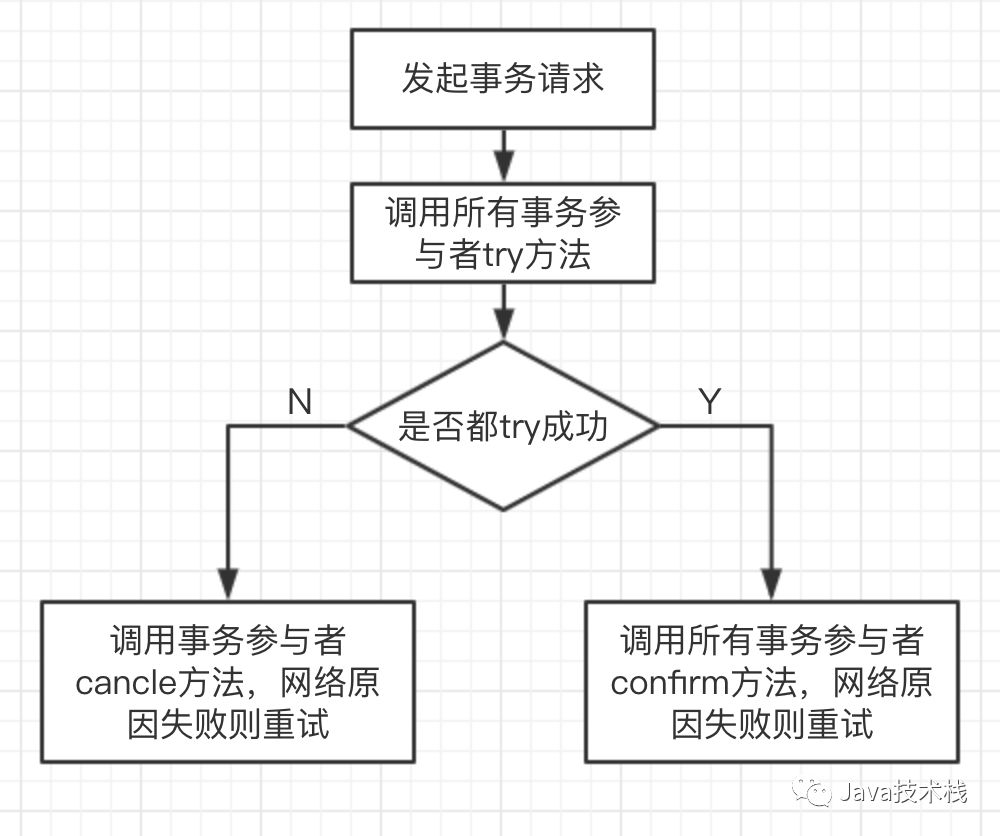
3.4.2 join问题
tddl、MyCAT等都支持跨分片join。但是尽力避免跨库join,比如通过字段冗余的方式等。
如果出现了这种情况且中间件支持分片join,那么可以这样使用。如果不支持可以手工查询。
四.总结
分表和在用途上不一样,分表是为了承接超大规模的表,单机放不下那种。分区的话则一般都是放在单机里的,用的比较多的是时间范围分区,方便归档。
性能稳定上的话都是一个个子表,差不多,区别应该是分区表是mysql内部实现的,会比分表方案少一点数据交互。
来源:http://www.cnblogs.com/GrimMjx/p/11772033.html
声明:本站所有文章,如无特殊说明或标注,均为本站原创发布。任何个人或组织,在未征得本站同意时,禁止复制、盗用、采集、发布本站内容到任何网站、书籍等各类媒体平台。如若本站内容侵犯了原著者的合法权益,可联系我们进行处理。



